
Cargando...
Zer egin dezaket?
tipo de documento Lecciones

El ácido desoxirribonucleico, conocido también por las siglas ADN, es un ácido nucleico que contiene las instrucciones genéticas usadas en el desarrollo y funcionamiento de todos los organismos vivos1 y algunos virus; también es responsable de la transmisión hereditaria. La función principal de la molécula de ADN es el almacenamiento a largo plazo de información para construir otros componentes de las células, como las proteínas y las moléculas de ARN. Los segmentos de ADN que llevan esta información genética son llamados genes, pero las otras secuencias de ADN tienen propósitos estructurales o toman parte en la regulación del uso de esta información genética.

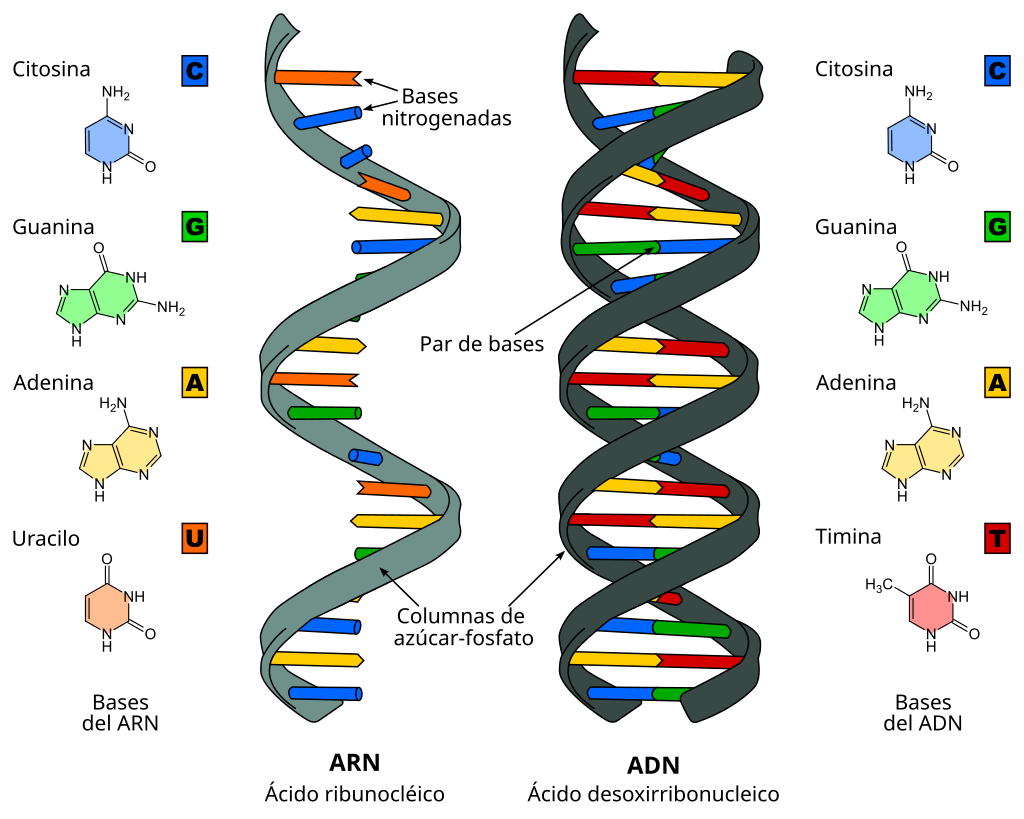
El ADN es un polímero de nucleótidos de adenina, guanina, citosina y timina, unidos por enlaces fosfodiéster, en el que un grupo fosfato queda unido por dos enlaces éster a dos nucleótidos sucesivos.
Cuando se unen dos nucleótidos por enlace fosfodiéster, el dinucleótido resultante tiene, en un extremo, un grupo fosfato en el carbono 5 que queda libre, y puede unirse a un grupo hidroxilo del carbono 3 de otro nucleótido. En el otro extremo, el grupo hidroxilo del carbono 3 también queda libre, disponible para reaccionar con el fosfato del carbono 5 de otro nucleótido. Así, se pueden formar largas cadenas de nucleótidos que siempre tendrán en un extremo un grupo 5' fosfato libre y en el otro un grupo hidroxilo 3' libre.
La secuencia de nucleótidos de un ácido nucleico se escribe de izquierda a derecha, desde el extremo del carbono 5 hasta el del 3.
Un ácido nucleico de cadena corta se denomina oligonucleótido (generalmente hasta 50 nucleótidos) y si su longitud es mayor, polinucleótido.
En las células eucariotas, el ADN se localiza en el núcleo, aunque también tienen ADN las mitocondrias y los cloroplastos.
El ADN del núcleo está asociado a unas proteínas llamadas histonas y a otras proteínas no histónicas. Estas proteínas son nucleoproteínas.
El ADN de las mitocondrias y de los cloroplastos es distinto del ADN nuclear, muy parecido al ADN de los procariotas. Este ADN forma un nucleoide que carece de envoltura nuclear, y también está asociado a otras proteínas.
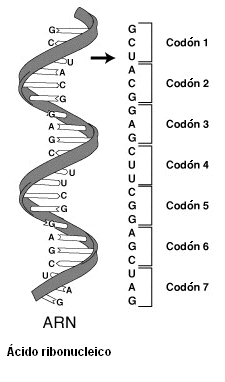
El código genético es el conjunto de reglas que permite la traducción de una secuencia de nucleótidos del ARNm a una secuencia de aminoácidos que constituye una proteína, en todos los seres vivos, lo que demuestra que ha tenido un origen único o universal, al menos en el contexto de nuestro planeta.
El código define la relación entre secuencias de tres nucleótidos, llamadas codones, y aminoácidos. De ese modo, cada codón se corresponde con un aminoácido específico.
La secuencia del material genético se compone de cuatro bases nitrogenadas distintas, que tienen una función equivalente a letras en el código genético: adenina (A), timina (T), guanina (G) y citosina (C) en el ADN y adenina (A), uracilo (U), guanina (G) y citosina (C) en el ARN.
La traducción del mensaje genético a proteínas se puede realizar gracias a este “diccionario” llamado código genético. Aunque sólo hay 20 aminoácidos distintos que codificar, sólo se disponen de 4 bases nitrogenadas distintas para hacerlo. Por tanto, hará falta más de una base nitrogenada para codificar cada aminoácido. Si fueran dos bases nitrogenadas, codificarían 42=16 parejas distintas de bases que codificarían 16 aminoácidos distintos. Y si fueran tres bases distintas (un triplete), codificarían, 43=64 tripletes distintos, lo que podría servir para codificar incluso a más de los 20 aminoácidos que existen.
Debido a esto, el número de codones posibles es 64:
Cada triplete (grupo de tres) nucleótidos de ARNm se llama codón. La secuencia de codones determina la secuencia de aminoácidos en una proteína en concreto, que tendrá una estructura y una función específica. Los tripletes del ADN que han sido transcritos a esos codones, se llaman codógenos.
El código genético tiene las siguientes características:
Aunque digamos que es universal, tiene algunas excepciones, como en las mitocondrias, protozoos y micoplasmas (un tipo de bacterias), cuyo código genético tiene alguna ligera diferencia.
Esto puede ser una ventaja, ya que si por error se cambia un nucleótido, puede ser que no codifique otro aminoácido distinto y se genere otra proteína.
La duplicación o replicación del ADN es el proceso mediante el que se sintetiza, a partir de una molécula de ADN, dos nuevas moléculas de ADN hijas con la misma secuencia de nucleótidos que la del ADN original.
La replicación tiene lugar en la fase S de la interfase del ciclo celular.
Como los seres vivos no son eternos, para que no se extinga la especie, tiene que haber un momento en el que se reproduzcan. Para originar estos individuos es necesario que pasen copias del ADN del progenitor o progenitores (si se forman por unión de gametos) a los descendientes. Excepcionalmente, sólo algunos virus contienen la información genética en forma de ARN.
El proceso de replicación del ADN es muy parecido tanto en organismos procariotas como en eucariotas. La doble hélice de ADN se abre, se separa y cada cadena actúa de molde para la síntesis de la nueva cadena con bases nitrogenadas complementarias a las de la cadena original.
Esta complementariedad entre las bases (G = C y A = T), son la esencia de la replicación, transcripción y traducción, todos los procesos en los que se transmite información.
Las principales características de la replicación del ADN son las siguientes:
Replicación semiconservativa
Durante la replicación, las dos cadenas de la molécula de ADN se separan. A partir de una molécula parental se obtienen dos moléculas hijas idénticas, cada una de ellas con una cadena antigua (parental) y una nueva.
Ocultar
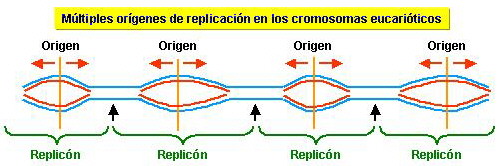
Replicación bidireccional
A partir del origen de replicación, la síntesis de las nuevas cadenas se realiza en sentidos opuestos. En el punto de origen de la replicación (ORI) se separan las cadenas originando una burbuja de replicación. Las cadenas se van separando, y se forma en cada cadena que va creciendo, en sentidos opuestos, una horquilla de replicación.
Replicación semidiscontinua
La replicación semidiscontinua del ADN está condicionada por:
A partir del punto de origen, en cada horquilla de replicación, se obtienen dos cadenas:
Aunque la replicación del ADN ocurre de un modo muy similar en todos los seres vivos, existen ciertas diferencias en la duplicación del ADN en procariotas y en eucariotas:

El ácido ribonucleico o ARN está formado por nucleótidos de ribosa, con las bases nitrogenadas adenina, guanina, citosina y uracilo. No tiene, pues, timina como el ADN, salvo el ARNt. La unión de los ribonucleótidos se realiza mediante enlaces fosfodiéster en sentido 5'→3', como en el ADN, pero el ARN casi siempre es monocatenario.
Aunque el ARN presenta una estructura primaria que es la secuencia de ribonucleótidos de la cadena, también tiene zonas plegadas en las que se establecen enlaces de hidrógeno entre las bases complementarias, A-U y G-C, originando una cierta estructura secundaria bicatenaria de doble hélice, similar a la del ADN.
El ARN se encarga de utilizar la información que contiene el ADN para poder realizar la síntesis de proteínas.
El ARN también tiene función biocatalizadora, por lo que se cree que, cuando se originó la vida, pudieron ser las primeras moléculas capaces de autoduplicarse, aunque después sería el ADN, con su cadena mucho más estable, el que se encargaría de almacenar la información genética.
Se puede encontrar ARN formado por una o dos cadenas:
El ARN está presente en muchos tipos de virus y en células procariotas y eucariotas.

Vamos a ver los siguientes tipos de ARN:
El ARN de transferencia es un tipo de ácido ribonucleico que se encarga de transportar los aminoácidos a los ribosomas donde, según la secuencia especificada en un ARN mensajero (transcrita, a su vez, del ADN), se sintetizan las proteínas.
El ARN soluble o de transferencia (ARNt) representa, aproximadamente, el 15 % de todo el ARN. Está formado por unos 80 nucleótidos, y se encuentra disperso en el citoplasma celular.
Existe una molécula de ARNt para cada aminoácido, con un triplete específico de bases nitrogenadas, el anticodón, que varía entre los distintos ARNt.
El ARNt es monocatenario, pero presenta zonas de complementariedad intracatenaria, es decir, zonas complementarias dentro de la misma cadena, lo que produce que se apareen dando una estructura característica semejante a la de un trébol de tres hojas. En la estructura secundaria de los ARNt se distinguen las siguientes características:
Aunque se hable de estructura en forma de hoja de trébol, en realidad, la molécula de ARNt se repliega, adquiriendo una estructura terciaria en forma de L.
Además de los nucleótidos típicos del ARN, como A, G, C y U, el ARNt, contiene otros que llevan bases metiladas, como la dihidrouridina (UH), la ribotimidina (T), la inosina (I), la metilguanosina (GMe), etcétera, que constituyen el 10% de los ribonucleótidos totales del ARNt.
La cadena de ARN presenta dos extremos:
Por tanto, el ARNt debe cumplir dos funciones:

El ARN mensajero (ARNm) es monocatenario, básicamente lineal. Sólo constituye el 2-5 % del ARN total.
La función del ARNm es tomar la información del ADN, que está en núcleo, y llevarla al citoplasma, donde están los ribosomas en los que se sintetizarán las proteínas con los aminoácidos aportados por los ARNt.
El ARNm se forma a partir de una hebra del ADN en un proceso llamado transcripción. Se crea, con las bases nitrogenadas complementarias, un molde con la información genética necesaria para la síntesis de proteínas. El tamaño del ARNm depende del tamaño de la proteína para la que lleva información. Después de realizar su función, la síntesis de la proteína, las enzimas ribonucleasas lo destruyen para evitar la producción innecesaria de proteínas. Cuando se vuelva a necesitar la síntesis de una proteína concreta, se creará nuevo ARNm.
La información que contiene el ARNm se presenta en una secuencia de bases nitrogenadas, agrupadas en tripletes o codones, cada uno de los cuales determina la unión de un determinado aminoácido.
El ARNm tiene distinta estructura en procariotas y en eucariotas.
ARNm en eucariotas
El ARN mensajero obtenido después de la transcripción se conoce como ARN transcrito primario o ARN precursor o pre-ARN, que en la mayoría de los casos no se libera del complejo de transcripción en forma totalmente activa, sino que ha de sufrir modificaciones antes de ejercer su función (procesamiento o maduración del ARN). Entre esas modificaciones se encuentran la eliminación de fragmentos (splicing), la adición de otros no codificados en el ADN y la modificación covalente de ciertas bases nitrogenadas.
El ARNm eucariótico se forma a partir del ARN transcrito primario (pre-ARNm), que está formado por dos tipos de segmentos que se alternan:
La maduración del ARN transcrito primario a ARN mensajero se produce en el núcleo, y es en ese proceso cuando se pierden los intrones.
El ARNm eucariótico posee en su extremo 5' una caperuza, formada por un nucleótido derivado de la guanina, que da estabilidad al ARNm y permite el acceso al ribosoma para la síntesis de proteínas. Después hay un segmento sin información, seguido de otro segmento con información que suele empezar con las bases A - U - G.
En el extremo 3' aparecen unos 200 nucleótidos de adenina, la llamada “cola” de poli-A, que estabiliza la molécula frente a las enzimas exonucleasas.
El ARNm eucariótico es monocistrónico, es decir, sólo contiene información para sintetizar una cadena polipeptídica.
ARNm en procariotas
El proceso de transcripción y el de traducción se realizan de manera similar que en las células eucariotas. La diferencia fundamental está en que, en las procariotas, el ARN mensajero no pasa por un proceso de maduración y, por lo tanto, no se le añade caperuza ni cola ni se le quitan intrones. Además, no tiene que salir del núcleo como en las eucariotas, porque en las células procariotas no hay un núcleo definido.
El ARNm en procariotas es policistrónico, contiene informaciones separadas para sintetizar distintas proteínas.
El ácido ribonucleico ribosómico o ribosomal (ARNr) es el tipo de ARN más abundante (80-85% del ARN total) en las células y constituye, en parte, los ribosomas. Estos se encargan de la síntesis de proteínas según la secuencia de nucleótidos presente en el ARN mensajero.
El ARN ribosómico constituye el 60 % del peso de los ribosomas.
El ARNr presenta segmentos lineales y segmentos en doble hélice (estructura secundaria), debido a la presencia de secuencias complementarias de ribonucleótidos a lo largo de la molécula.
El peso de los ARNr y de los ribosomas se suele expresar según el coeficiente de sedimentación (s) de Svedberg, que es directamente proporcional a la velocidad de sedimentación de la partícula durante la ultracentrifugación. El coeficiente de sedimentación se expresa en unidades svedberg (S), siendo un svedberg equivalente a 10-13 segundos.
Las células procariotas presentan ribosomas de 70 S, menor peso que los de las células eucariotas, de 80 S.
El ARN nucleolar (ARNn) forma parte del nucléolo. Se origina a partir de la región del ADN denominada región organizadora nucleolar (NOR). Este ARN monocatenario de 45 S se asocia a proteínas procedentes el citoplasma para formar las subunidades de los ribosomas.
El ARN pequeño nuclear (ARNpn), llamado así por su pequeño tamaño por encontrarse en el núcleo de las células eucariotas. También se le denomina ARN-U, por su elevado contenido en uracilo. Como los demás ARN, el ARNpn es monocatenario.
El ARNpn se une a ciertas proteínas del núcleo formando las ribonucleoproteínas nucleares, para realizar el proceso de eliminación de intrones (maduración del ARNm).
Texto:
Imagen:
El ácido desoxirribonucleico, conocido también por las siglas ADN, es un ácido nucleico que contiene las instrucciones genéticas usadas en el desarrollo y funcionamiento de todos los organismos vivos1 y algunos virus; también es responsable de la transmisión hereditaria. La función principal de la molécula de ADN es el almacenamiento a largo plazo de información para construir otros componentes de las células, como las proteínas y las moléculas de ARN. Los segmentos de ADN que llevan esta información genética son llamados genes, pero las otras secuencias de ADN tienen propósitos estructurales o toman parte en la regulación del uso de esta información genética.
El ADN es un polímero de nucleótidos de adenina, guanina, citosina y timina, unidos por enlaces fosfodiéster, en el que un grupo fosfato queda unido por dos enlaces éster a dos nucleótidos sucesivos.
Cuando se unen dos nucleótidos por enlace fosfodiéster, el dinucleótido resultante tiene, en un extremo, un grupo fosfato en el carbono 5 que queda libre, y puede unirse a un grupo hidroxilo del carbono 3 de otro nucleótido. En el otro extremo, el grupo hidroxilo del carbono 3 también queda libre, disponible para reaccionar con el fosfato del carbono 5 de otro nucleótido. Así, se pueden formar largas cadenas de nucleótidos que siempre tendrán en un extremo un grupo 5' fosfato libre y en el otro un grupo hidroxilo 3' libre.
La secuencia de nucleótidos de un ácido nucleico se escribe de izquierda a derecha, desde el extremo del carbono 5 hasta el del 3.
Un ácido nucleico de cadena corta se denomina oligonucleótido (generalmente hasta 50 nucleótidos) y si su longitud es mayor, polinucleótido.
En las células eucariotas, el ADN se localiza en el núcleo, aunque también tienen ADN las mitocondrias y los cloroplastos.
El ADN del núcleo está asociado a unas proteínas llamadas histonas y a otras proteínas no histónicas. Estas proteínas son nucleoproteínas.
El ADN de las mitocondrias y de los cloroplastos es distinto del ADN nuclear, muy parecido al ADN de los procariotas. Este ADN forma un nucleoide que carece de envoltura nuclear, y también está asociado a otras proteínas.
El código genético es el conjunto de reglas que permite la traducción de una secuencia de nucleótidos del ARNm a una secuencia de aminoácidos que constituye una proteína, en todos los seres vivos, lo que demuestra que ha tenido un origen único o universal, al menos en el contexto de nuestro planeta.
El código define la relación entre secuencias de tres nucleótidos, llamadas codones, y aminoácidos. De ese modo, cada codón se corresponde con un aminoácido específico.
La secuencia del material genético se compone de cuatro bases nitrogenadas distintas, que tienen una función equivalente a letras en el código genético: adenina (A), timina (T), guanina (G) y citosina (C) en el ADN y adenina (A), uracilo (U), guanina (G) y citosina (C) en el ARN.
La traducción del mensaje genético a proteínas se puede realizar gracias a este “diccionario” llamado código genético. Aunque sólo hay 20 aminoácidos distintos que codificar, sólo se disponen de 4 bases nitrogenadas distintas para hacerlo. Por tanto, hará falta más de una base nitrogenada para codificar cada aminoácido. Si fueran dos bases nitrogenadas, codificarían 42=16 parejas distintas de bases que codificarían 16 aminoácidos distintos. Y si fueran tres bases distintas (un triplete), codificarían, 43=64 tripletes distintos, lo que podría servir para codificar incluso a más de los 20 aminoácidos que existen.
Debido a esto, el número de codones posibles es 64:
Cada triplete (grupo de tres) nucleótidos de ARNm se llama codón. La secuencia de codones determina la secuencia de aminoácidos en una proteína en concreto, que tendrá una estructura y una función específica. Los tripletes del ADN que han sido transcritos a esos codones, se llaman codógenos.
El código genético tiene las siguientes características:
Aunque digamos que es universal, tiene algunas excepciones, como en las mitocondrias, protozoos y micoplasmas (un tipo de bacterias), cuyo código genético tiene alguna ligera diferencia.
Esto puede ser una ventaja, ya que si por error se cambia un nucleótido, puede ser que no codifique otro aminoácido distinto y se genere otra proteína.
La duplicación o replicación del ADN es el proceso mediante el que se sintetiza, a partir de una molécula de ADN, dos nuevas moléculas de ADN hijas con la misma secuencia de nucleótidos que la del ADN original.
La replicación tiene lugar en la fase S de la interfase del ciclo celular.
Como los seres vivos no son eternos, para que no se extinga la especie, tiene que haber un momento en el que se reproduzcan. Para originar estos individuos es necesario que pasen copias del ADN del progenitor o progenitores (si se forman por unión de gametos) a los descendientes. Excepcionalmente, sólo algunos virus contienen la información genética en forma de ARN.
El proceso de replicación del ADN es muy parecido tanto en organismos procariotas como en eucariotas. La doble hélice de ADN se abre, se separa y cada cadena actúa de molde para la síntesis de la nueva cadena con bases nitrogenadas complementarias a las de la cadena original.
Esta complementariedad entre las bases (G = C y A = T), son la esencia de la replicación, transcripción y traducción, todos los procesos en los que se transmite información.
Las principales características de la replicación del ADN son las siguientes:
Replicación semiconservativa
Durante la replicación, las dos cadenas de la molécula de ADN se separan. A partir de una molécula parental se obtienen dos moléculas hijas idénticas, cada una de ellas con una cadena antigua (parental) y una nueva.
Ocultar
Replicación bidireccional
A partir del origen de replicación, la síntesis de las nuevas cadenas se realiza en sentidos opuestos. En el punto de origen de la replicación (ORI) se separan las cadenas originando una burbuja de replicación. Las cadenas se van separando, y se forma en cada cadena que va creciendo, en sentidos opuestos, una horquilla de replicación.
Replicación semidiscontinua
La replicación semidiscontinua del ADN está condicionada por:
A partir del punto de origen, en cada horquilla de replicación, se obtienen dos cadenas:
Aunque la replicación del ADN ocurre de un modo muy similar en todos los seres vivos, existen ciertas diferencias en la duplicación del ADN en procariotas y en eucariotas:
El ácido ribonucleico o ARN está formado por nucleótidos de ribosa, con las bases nitrogenadas adenina, guanina, citosina y uracilo. No tiene, pues, timina como el ADN, salvo el ARNt. La unión de los ribonucleótidos se realiza mediante enlaces fosfodiéster en sentido 5'→3', como en el ADN, pero el ARN casi siempre es monocatenario.
Aunque el ARN presenta una estructura primaria que es la secuencia de ribonucleótidos de la cadena, también tiene zonas plegadas en las que se establecen enlaces de hidrógeno entre las bases complementarias, A-U y G-C, originando una cierta estructura secundaria bicatenaria de doble hélice, similar a la del ADN.
El ARN se encarga de utilizar la información que contiene el ADN para poder realizar la síntesis de proteínas.
El ARN también tiene función biocatalizadora, por lo que se cree que, cuando se originó la vida, pudieron ser las primeras moléculas capaces de autoduplicarse, aunque después sería el ADN, con su cadena mucho más estable, el que se encargaría de almacenar la información genética.
Se puede encontrar ARN formado por una o dos cadenas:
El ARN está presente en muchos tipos de virus y en células procariotas y eucariotas.
Vamos a ver los siguientes tipos de ARN:
El ARN de transferencia es un tipo de ácido ribonucleico que se encarga de transportar los aminoácidos a los ribosomas donde, según la secuencia especificada en un ARN mensajero (transcrita, a su vez, del ADN), se sintetizan las proteínas.
El ARN soluble o de transferencia (ARNt) representa, aproximadamente, el 15 % de todo el ARN. Está formado por unos 80 nucleótidos, y se encuentra disperso en el citoplasma celular.
Existe una molécula de ARNt para cada aminoácido, con un triplete específico de bases nitrogenadas, el anticodón, que varía entre los distintos ARNt.
El ARNt es monocatenario, pero presenta zonas de complementariedad intracatenaria, es decir, zonas complementarias dentro de la misma cadena, lo que produce que se apareen dando una estructura característica semejante a la de un trébol de tres hojas. En la estructura secundaria de los ARNt se distinguen las siguientes características:
Aunque se hable de estructura en forma de hoja de trébol, en realidad, la molécula de ARNt se repliega, adquiriendo una estructura terciaria en forma de L.
Además de los nucleótidos típicos del ARN, como A, G, C y U, el ARNt, contiene otros que llevan bases metiladas, como la dihidrouridina (UH), la ribotimidina (T), la inosina (I), la metilguanosina (GMe), etcétera, que constituyen el 10% de los ribonucleótidos totales del ARNt.
La cadena de ARN presenta dos extremos:
Por tanto, el ARNt debe cumplir dos funciones:
El ARN mensajero (ARNm) es monocatenario, básicamente lineal. Sólo constituye el 2-5 % del ARN total.
La función del ARNm es tomar la información del ADN, que está en núcleo, y llevarla al citoplasma, donde están los ribosomas en los que se sintetizarán las proteínas con los aminoácidos aportados por los ARNt.
El ARNm se forma a partir de una hebra del ADN en un proceso llamado transcripción. Se crea, con las bases nitrogenadas complementarias, un molde con la información genética necesaria para la síntesis de proteínas. El tamaño del ARNm depende del tamaño de la proteína para la que lleva información. Después de realizar su función, la síntesis de la proteína, las enzimas ribonucleasas lo destruyen para evitar la producción innecesaria de proteínas. Cuando se vuelva a necesitar la síntesis de una proteína concreta, se creará nuevo ARNm.
La información que contiene el ARNm se presenta en una secuencia de bases nitrogenadas, agrupadas en tripletes o codones, cada uno de los cuales determina la unión de un determinado aminoácido.
El ARNm tiene distinta estructura en procariotas y en eucariotas.
ARNm en eucariotas
El ARN mensajero obtenido después de la transcripción se conoce como ARN transcrito primario o ARN precursor o pre-ARN, que en la mayoría de los casos no se libera del complejo de transcripción en forma totalmente activa, sino que ha de sufrir modificaciones antes de ejercer su función (procesamiento o maduración del ARN). Entre esas modificaciones se encuentran la eliminación de fragmentos (splicing), la adición de otros no codificados en el ADN y la modificación covalente de ciertas bases nitrogenadas.
El ARNm eucariótico se forma a partir del ARN transcrito primario (pre-ARNm), que está formado por dos tipos de segmentos que se alternan:
La maduración del ARN transcrito primario a ARN mensajero se produce en el núcleo, y es en ese proceso cuando se pierden los intrones.
El ARNm eucariótico posee en su extremo 5' una caperuza, formada por un nucleótido derivado de la guanina, que da estabilidad al ARNm y permite el acceso al ribosoma para la síntesis de proteínas. Después hay un segmento sin información, seguido de otro segmento con información que suele empezar con las bases A - U - G.
En el extremo 3' aparecen unos 200 nucleótidos de adenina, la llamada “cola” de poli-A, que estabiliza la molécula frente a las enzimas exonucleasas.
El ARNm eucariótico es monocistrónico, es decir, sólo contiene información para sintetizar una cadena polipeptídica.
ARNm en procariotas
El proceso de transcripción y el de traducción se realizan de manera similar que en las células eucariotas. La diferencia fundamental está en que, en las procariotas, el ARN mensajero no pasa por un proceso de maduración y, por lo tanto, no se le añade caperuza ni cola ni se le quitan intrones. Además, no tiene que salir del núcleo como en las eucariotas, porque en las células procariotas no hay un núcleo definido.
El ARNm en procariotas es policistrónico, contiene informaciones separadas para sintetizar distintas proteínas.
El ácido ribonucleico ribosómico o ribosomal (ARNr) es el tipo de ARN más abundante (80-85% del ARN total) en las células y constituye, en parte, los ribosomas. Estos se encargan de la síntesis de proteínas según la secuencia de nucleótidos presente en el ARN mensajero.
El ARN ribosómico constituye el 60 % del peso de los ribosomas.
El ARNr presenta segmentos lineales y segmentos en doble hélice (estructura secundaria), debido a la presencia de secuencias complementarias de ribonucleótidos a lo largo de la molécula.
El peso de los ARNr y de los ribosomas se suele expresar según el coeficiente de sedimentación (s) de Svedberg, que es directamente proporcional a la velocidad de sedimentación de la partícula durante la ultracentrifugación. El coeficiente de sedimentación se expresa en unidades svedberg (S), siendo un svedberg equivalente a 10-13 segundos.
Las células procariotas presentan ribosomas de 70 S, menor peso que los de las células eucariotas, de 80 S.
El ARN nucleolar (ARNn) forma parte del nucléolo. Se origina a partir de la región del ADN denominada región organizadora nucleolar (NOR). Este ARN monocatenario de 45 S se asocia a proteínas procedentes el citoplasma para formar las subunidades de los ribosomas.
El ARN pequeño nuclear (ARNpn), llamado así por su pequeño tamaño por encontrarse en el núcleo de las células eucariotas. También se le denomina ARN-U, por su elevado contenido en uracilo. Como los demás ARN, el ARNpn es monocatenario.
El ARNpn se une a ciertas proteínas del núcleo formando las ribonucleoproteínas nucleares, para realizar el proceso de eliminación de intrones (maduración del ARNm).
Texto:
Imagen:
Mira un ejemplo de lo que te pierdes
Kategoriak:
Aipatu nahi al duzu? Erregistratu o Hasi saioa
Si ya eres usuario, Inicia sesión




















Didactalia-ri Gehitzea Arrastra el botón a la barra de marcadores del navegador y comparte tus contenidos preferidos. Más info...















Aipatu
0